[TOC]
Transformer 有两种变体,它们分别捕获瞬时结构信息和时间演化信息,以及一种新的关系连续时间编码函数,以促进 Hawkes 过程的特征演化。
注意:
在这篇论文里里面,我们舍弃了 RGCN 领域聚合器,(RGCN可以考虑多跳和多邻居的信息)
但是:
R-GCN无法充分利用查询信息。
基于 RNN 的模型假设序列等距,这与现实生活中的事件序列不一致。
逐步推理方法在训练期间累积错误。
他们无法预测未来事件发生的时间戳。
论文一共引入了两个transformer 一个捕获结构信息,一个捕获时间演化信息
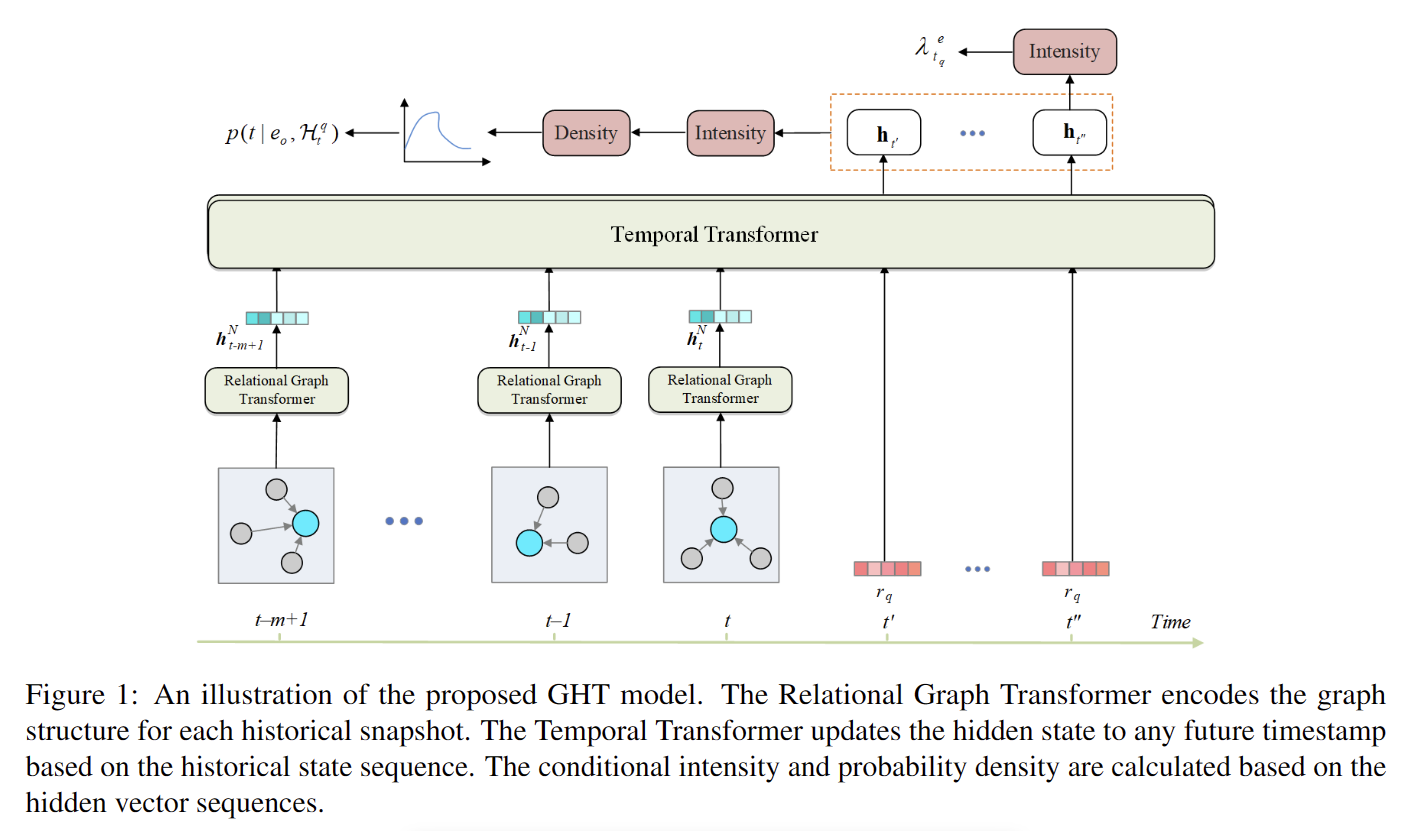
和其他Hawkes过程一样,都是计算强度计算密度
结构信息: 一个变体用于聚合多关系图,捕获每个时间戳的结构信息并生成特征向量。该模型可以学习哪些交互在具有注意机制的查询中更为关键。
时间演化信息: 另一个变体基于特征向量序列捕获时间信息,同时为未来每个时间戳输出一个隐藏状态。最后,该模型使用隐藏状态来计算条件强度,然后得到下一个事件的候选实体分数或时间概率密度。
下面我们给出 强度函数的定义:
所以读到这里我会有疑问? 改进一下强度函数是不是一个更大的创新,毕竟这是已经用了好久的
Reational Graph Transformer
设计了一个Reational Graph Transformer,让我们的模型知道哪些并发事件在快照中更为关键。有两种图形表示形式:全局感受野 和局部感受野
感受野
全局感受野(Global Receptive Field)和局部感受野(Local Receptive Field)是在计算机视觉领域中常用的概念,用于描述神经网络中每个神经元所“看到”的输入数据范围。
局部感受野指的是神经网络中每个神经元接收的输入数据的局部范围。在卷积神经网络(Convolutional Neural Network, CNN)中,每个卷积层的神经元只与其上一层的一部分神经元连接,并且只关注他们在输入数据空间上的局部位置。
全局感受野则是指神经网络中每个神经元能够接收到的整体输入数据范围。在多层网络中,随着信息的传递和特征提取,神经元的感受野会逐渐扩大。从第一个卷积层开始,每个卷积层都会通过滤波器的操作将输入数据的局部特征转化为更高级的抽象特征。因此,通过堆叠多个卷积层,每个神经元最终能够感受到更广阔的输入数据范围,即全局感受野。
全局感受野和局部感受野的概念对于理解神经网络的工作原理和特征提取的过程非常重要。在设计和调整神经网络架构时,合理地使用全局感受野和局部感受野可以帮助提高特征的表达能力和模型的性能。
E R 实体关系矩阵嵌入 RGT 聚合来自时序序列中每个实体的每个传入边的结构信息。
我们将节点的隐藏状态初始化为相应实体的初始嵌入,每个节点将通过消息传递框架更新其隐藏状态
例如,对于实体e ,我们将源节点的隐藏状态和相应的关系嵌入连接起来,作为每个传入边edge的消息
当做key K value V ∈M×2d 其中 M为消息 message的数量
我们将所有可定义的参数的维度定义为d
query Q ∈ M×d 实体在层l∈[1,N]的隐藏状态定义如下:
最后,我们输出查询实体的隐藏状态序列 H。我们没有在查询矩阵Q中引入查询实体信息e,因为随着TKG的发展,图中可能会出现新的实体,并且该模型没有学习它们的初始嵌入。相比之下,关系的语义是稳定的和上下文无关的,因此所有层共享关系嵌入矩阵。
为什么是 所有层共享关系嵌入矩阵
(关系的语义是指不同实体之间可能存在的关联或联系,例如“父亲”、“朋友”等。在知识图谱和关系抽取等任务中,需要将关系映射为一个密集向量,即关系嵌入(Relation Embedding),以进行后续的计算和推理。
在自然语言处理和机器学习领域中,通常将语义表示为一个向量空间中的向量。在关系嵌入中,将每个关系映射到向量空间中的一个点,并且关系之间的距离可以用来衡量它们之间的相似程度。因此,关系嵌入是一个很重要的问题。
在建立关系嵌入模型时,需要确定嵌入向量的维度和具体数值。为了实现关系嵌入的共享,可以采用共享关系嵌入矩阵的方法。这意味着所有的层都可以使用相同的关系嵌入矩阵,而无需为每个层分别进行学习。这种共享方式可以减少模型参数,避免过拟合,并且使得模型更易于训练。
同时,因为关系的语义是稳定的且上下文无关的,即在不同句子和语境中,同一种关系的语义是相同的,因此所有层可以共享一个关系嵌入矩阵。这种共享方式可以保证模型的稳定性和一致性,避免了每一层产生不同的关系嵌入结果,导致模型效果下降。
综上所述,共享关系嵌入矩阵的方式可以减少模型参数、避免过拟合,并且保证模型的稳定性和一致性,从而提高模型的性能和泛化能力。)
Temporal Transformer
设计了 Temporal Transformer (TT) 来模拟连续时间域中实体表示的时间演化。
Transformer 通过位置编码函数学习位置信息。
考虑?我们的 输入是图信息聚合后的连续向量,而不是离散域
对于不同的查询事件类型,注意力的时间分布可能不同
重新设计了一个关系连续时间编码函数来辅助注意力计算。我们需要确保函数的归纳能力,因为在模型训练中看不到未来的时间戳。基于 Transformer attention 的计算原理,
我们可以使用绝对时间编码来表示相对时间信息。
query 和 key的 时间编码信息
上面的关系矩阵是关系矩阵r的线性映射,w为d维的学习参数
时间嵌入向量作为
Conditional Intensity
我们可以在未来随时生成隐藏表示。然后,我们可以使用它为所有候选实体构建一个连续时间条件强度函数
获得了强度函数之后就可以用来预测了。
对于积分运算,我们使用梯形规则来近似:也可以选择其他的积分近似规则
Training
我们将实体预测任务视为多类分类任务,将时间预测任务视为回归任务。
然后,我们对实体预测任务使用交叉熵损失和时间预测任务使用均方误差
(MSE) 损失。令 D training表示训练集,Le 是实体预测的损失,而
Lt是时间预测的损失。然后,
the finally loss
我们将所有嵌入和隐藏状态的维度设置为 100。历史长度限制为 6。关系图 Transformer 的层数设置为 2,注意力头数设置为 1。对于 Temporal Transformer,层数为 2,注意力头数为 2。我们将 dropout 率为 50% 的 dropout 应用于每一层,并使用标签平滑来抑制过度拟合。用于损失函数的超参数设置为0.2。我们使用ADAM来优化参数,学习率为0.003,权重衰减为0.0001。批次大小设置为256。所有实验都是在特斯拉P100上进行的。
关系连续时间编码可以有效地捕获时间信息并帮助模型获得良好的性能。
未来展望
GHT 的推理完全依赖于学习的实体表示,随着 TKG 的发展而出现的新实体将得到随机初始化,这限制了模型的归纳偏差能力。
在进行时间预测时,积分运算是通过近似估计实现的。估计越准确,需要更多的计算。Transformer 中的注意力计算也是二次复杂度,需要大量的计算。
所有这些因素都限制了 GHT 处理大规模图的能力。

