[TOC]
CENET 学习历史和非历史依赖来区分可以与给定查询最佳匹配的最潜在实体。
通过启动对比学习来研究当前时刻是否更多地依赖于历史或非历史事件
表示进一步帮助训练一个二元分类器,其输出是一个布尔掩码来指示搜索空间中的相关实体
之前的是多关注于周期性和重复性的事件
对于重复或周期性事件,模型预计会优先考虑一些频繁出现的实体,对于新事件,模型应该更多地关注历史交互较少的实体。
历史和非历史实体,通过对比学习确认
(𝑠, 𝑟, ?, 𝑡 )
首先采用基于复制机制的评分策略对历史和非历史事件的依赖性进行建模。(基于复制机制的评分机制是一种通过为数据副本赋予权重或分数来管理分布式系统中数据复制和访问的方法,以提供高可用性、容错性和性能优化。)
突出贡献:
1.提出了CENET,不仅可以通过联合调查历史和非历史信息来预测重复和周期性事件,还可以预测潜在的新事件;
2.引用了对比学习来来分辨高相关的实体
对比学习损失函数
METHOD
1.预设参数
我们将粗体s,p, o 分别用于 s、p 和 o 的嵌入向量,其维度为 d。E 是所有实体的嵌入,其行表示实体的嵌入向量,例如 s 和 o。类似地,P是所有关系类型的嵌入。
对于给定query(𝑠, 𝑟, ?, 𝑡 ),我们设定
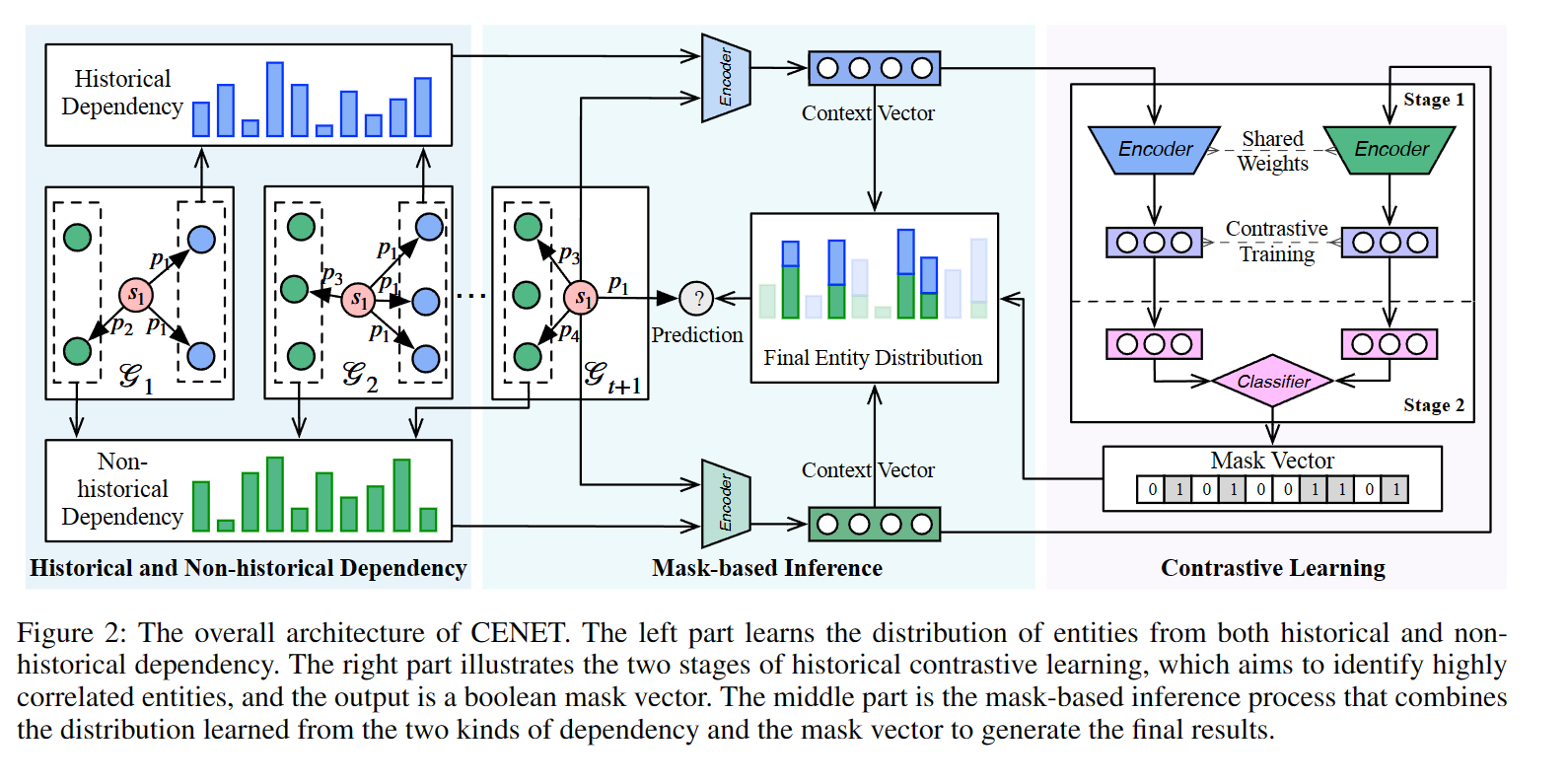
历史和非历史依赖
在大多数 TKG 中,尽管许多事件通常表现出重复的出现模式,但新事件可能没有历史事件来指代。
在preprocess首先 对给定query q = (s, p,?, t)
研究给定查询的历史实体的频率
由于我们无法计算非历史实体的频率,CENET变换
下一步根据
复制机制是一种用于生成式模型中的技术,主要应用于序列到序列(Sequence-to-Sequence)任务,如机器翻译、文本摘要等。复制机制允许模型从输入序列中直接复制一些信息,将其作为输出序列的一部分。这种机制对于包含罕见或未知词汇、实体或短语的输入序列非常有用,可以提高模型生成结果的准确性和流畅性。
从两个方面捕获不同类型的依赖关系:一个是查询和集合之间的相似度得分向量实体,另一个是查询的相应频率信息与复制机制。
CENET 为查询 q
生成一个潜在上下文向量,对不同对象实体的历史依赖性进行评分
我们添加复制项来改变历史实体的索引分数,直接指向更高的值,而不会对梯度更新做出贡献。
同理
在推理过程中,CENET 将上述两个潜在上下文向量的 softmax
结果组合为所有对象实体的预测概率
历史对比学习
显然,上面定义的学习机制很好地捕捉了每个查询的历史和非历史依赖性。但是,许多重复和周期性事件仅与历史实体相关联。此外,对于新事件,现有模型可能会忽略那些历史交互较少的实体,并预测经常与其他事件交互的错误实体。所提出的历史对比学习训练查询的对比表示,以识别查询级别的少量高度相关的实体。
首先是Iq,用来确定查询q的时候,缺失值是否在历史实体的集合当中。
stage 1 : 学习对比表示
该模型通过最小化监督对比损失来学习查询的对比表示,该损失将 Iq 为正作为训练标准,以尽可能分离语义空间中不同查询的表示。
设 vq 是给定查询 q 的嵌入向量(表示):
令 M 表示 minibatch,Q(q) 表示 M 中的查询集,除了 q 的布尔标签与 Iq
相同,如下所示:
stage 2 : 训练二元分类器
第一阶段的训练完成后,CENET在第一阶段冻结相应参数的权重,包括E、P及其编码器。然后它将 vq 馈送到线性层,以根据基本事实 Iq 训练具有交叉熵损失的二元分类器,这很容易提及。现在,分类器可以识别query q的缺失对象实体是否存在于历史实体集中。
在推理过程中,生成一个布尔掩码向量,根据预测的 Iq 以及
o是否为真来识别应该关注哪种实体:

参数学习
其中 α 是一个从 0 到 1 的超参数,以平衡不同的损失。在第二阶段,我们选择具有 sigmoid 激活的二进制交叉熵来训练二元分类器。
这样的训练过程也用于预测实验中缺失的主题实体。
α =0.2 最好 拉姆达为2最好
从CENET 结构图 可以看出,中间部分分别说明了从两侧接收分布
结论和未来发展
在本文中,我们提出了一种新的时间知识图表示学习模型--对比事件网络(CENET),用于事件预测。CENET的核心思想是学习整个实体集的令人信服的分布,并在对比学习框架下从历史和非历史依赖中识别出重要的实体。实验结果表明,CENET 在大多数指标上都显着优于所有现有方法,尤其是对于 Hits@1。有希望的未来工作包括探索对比学习在知识图中的能力,例如找到更合理的对比对。

